> The skull architecture of oracle is same as normal machine/ system its has similar components like RAM, CPU, and STORAGE, in oracle they are called as Buffer, Process, Storage.
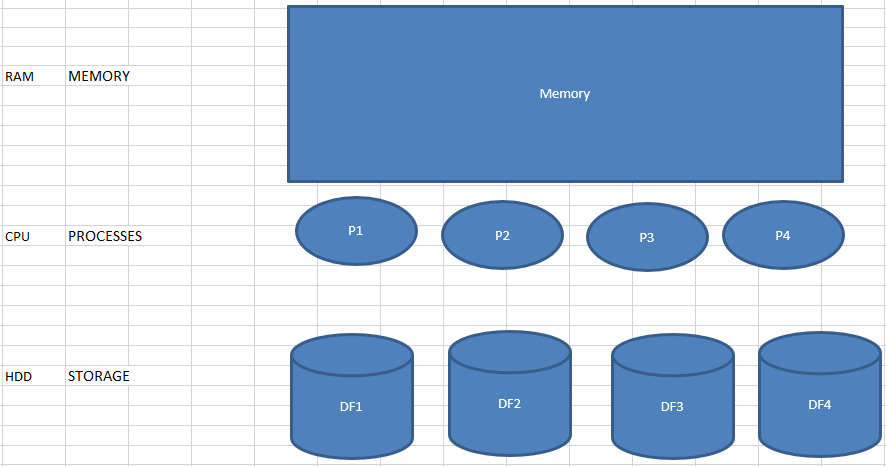
The Main Architecture of oracle and the components present in it are:
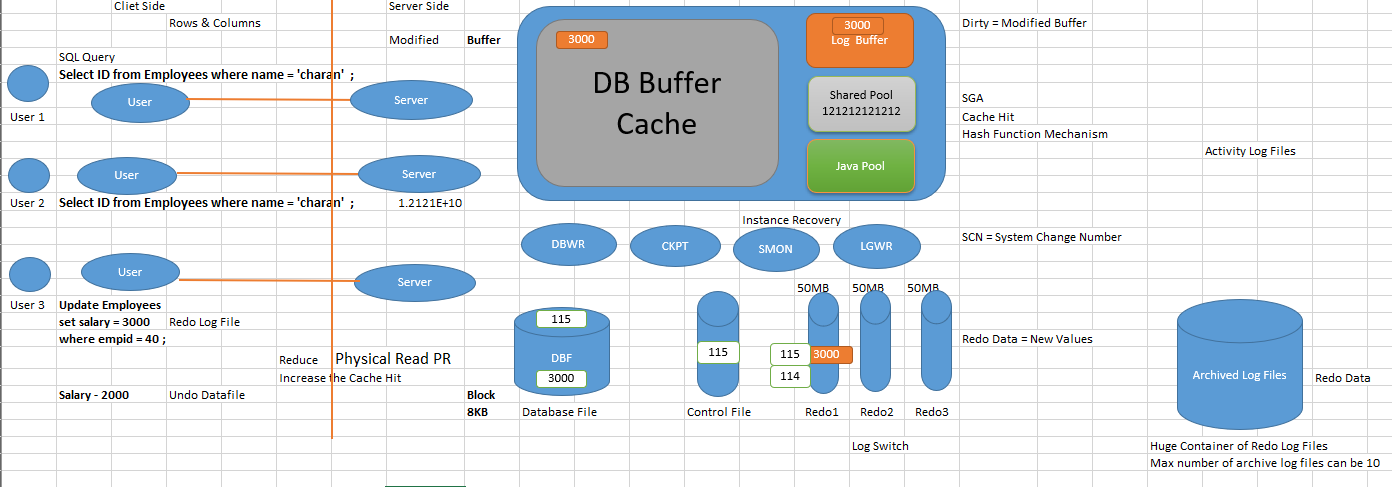
There are three main structures in Oracle Database structure architecture they are
- Memory structures (Similar to RAM)
- Process structures(Similar to CPU)
- Storage structures(Similar to Storage)
> And here the database(storage) consists of physical and logical structures
> Instance is the combination of Memory structure(SGA) and Process structure (background-process).
> Coming from left in the architecture a connection establishment to a database by a user
For every user to connect to database an user process and server process is created which establishes a connection/session between user and database.
Connection: Communication between user process and an instance. (Physical communication)
Some main components of memory structure:
Two basic memory structures associated with an instance are SGA and PGA
SGA - System Global Area:
This is a shared memory common to all the users logging in, there are some of the components combined called as SGA and the components are Shared Pool, Large Pool, Java Pool, Streams Pool, Database buffer cache, Redo log buffer, KEEP Buffer pool, RECYCLE buffer Pool, nK buffer cache.
The SGA is the shared memory area that contains data and control information for the instance. The SGA includes the following components:
- Shared pool: Caches various constructs that can be shared among users, The shared pool portion of the SGA contains the library cache, the data dictionary cache, the SQL query result cache, the PL/SQL function result cache, buffers for parallel execution messages, and control structures.
A shared SQL area contains the parse tree and execution plan for a given SQL statement. Oracle Database saves memory by using one shared SQL area for SQL statements run multiple times, which often happens when many users run the same application,
When a new SQL statement is parsed, Oracle Database allocates memory from the shared pool to store in the shared SQL area. The size of this memory depends on the complexity of the statement
- Database buffer cache: Caches blocks of data retrieved from the database, Hold copies of data blocks that are read from datafiles, and is shared by all concurrent users to satisfy the read consistency model. All users who are concurrently connected to the instance share access to the database buffer cache.
The first time an Oracle Database user process requires a particular piece of data, it searches for the data in the database buffer cache.
If the process finds the data already in the cache (a cache hit), it can read the data directly from memory. If the process cannot find the data in the cache (a cache miss),
It must copy the data block from a data file on disk into a buffer in the cache before accessing the data. Accessing data through a cache hit is faster than data access through a cache miss.
- Redo log buffer: Caches redo information (used for instance recovery) until it can be written to the physical redo log files stored on the disk.
The redo log buffer is a circular buffer in the SGA that holds information about changes made to the database. Redo entries contain the information necessary to reconstruct (or redo) changes that are made to the database by DML, DDL, or internal operations. Redo entries are used for database recovery if necessary.
As the server process makes changes to the buffer cache, redo entries are generated and written to the redo log buffer in the SGA. The redo entries take up continuous, sequential space in the buffer. The log writer background process writes the redo log buffer to the active redo log file (or group of files) on disk.
- Large Pool: The database administrator can configure an optional memory area called the large pool. To provide large memory allocations for
- Session memory for the shared server and the Oracle XA interface
- I/O server processes
- Oracle Database backup and restore operations
- Parallel Query operations
- Advanced Queuing memory table storage
The large pool is better able to satisfy such large memory requests than the shared pool The large pool is not managed by a least recently used (LRU) list.
- Java pool: Used for all session-specific Java code and data in the Java Virtual Machine (JVM), Java pool memory is used in different ways, depending on the mode in which Oracle Database is running.
- Streams pool: Used by Oracle Streams to store information required by capture and apply.
- KEEP buffer pool: A specialized type of database buffer cache that is tuned to retain blocks of data in memory for long periods of time
- nK buffer cache: One of several specialized database buffer caches designed to hold block sizes different than the default database block size
- RECYCLE buffer pool: A specialized type of database buffer cache that is tuned to recycle or remove block from memory quickly
PGA - Program Global Area:
This is an individual memory structure for every server process a PGA is associated with it, this is individual memory to individual users logging in simply said its a non shared memory.
A Program Global Area (PGA) is a private memory region that contains data and control information for each server process. An Oracle server process services a client’s requests. Each server process has its own private PGA that is allocated when the server process is started.
The PGA is divided into two major areas: Stack Space and the User Global Area (UGA).
Each user connecting to the database instance has a separate server process. For this type of connection, the PGA contains a subdivision of memory known as the User Global Area (UGA). The UGA is composed of the following
- Cursor area for storing runtime information on cursors
- User session data storage area for control information about a session
- SQL working areas for processing SQL statements consisting of:
- A sort area for functions that order data such as ORDER BY and GROUP BY
- A hash area for performing hash joins of tables
- A create bitmap area used in bitmap index creation common to data warehouses
- A bitmap merge area used for resolving bitmap index plan execution
This PGA is not a part of an instance, only SGA is the part of a instance.
Some of the Process structures(Background process):
There are three types of Process in oracle they are
- User process: is the application or tool that connects to oracle database.
- Database processes
- Server process: Connects to the instance and is started when a user establishes a session
- Background processes: Are started when an oracle instance is started.
- Application processes: Networking Listeners and Grid infrastructure daemons
Some of the Background process are
Required:
- Database writer process (DBWn): Writes modified(dirty) buffers in database buffer cache to disk/datafiles, Although one Database Writer process (DBW0) is adequate for most systems, you can configure additional processes (DBW1 through DBW9 and DBWa through DBWz) to improve write performance.
- Log writer process (LGWR): The Log Writer process (LGWR) is responsible for redo log buffer management by writing the redo log buffer entries to a redo log file on disk. LGWR writes all redo entries that have been copied into the buffer since the last time it wrote.
The redo log buffer is a circular buffer. When LGWR writes redo entries from the redo log buffer to a redo log file, server processes can then copy new entries over the entries in the redo log buffer that have been written to disk.
LGWR writes the logs:
- When a user process commits a transaction.
- When the redo log buffer is one-third full.
- Before a DBWn process writes modified buffers to disk (if necessary).
- Every three seconds.
- Checkpoint process (CKPT): A checkpoint is a data structure that defines a system change number (SCN) in the redo thread of a database.
Checkpoints are recorded in the control file and in each data file header. They are a crucial element of recovery.When a checkpoint occurs, Oracle Database must update the headers of all data files to record the details of the checkpoint. This is done by the CKPT process.
- System monitor process (SMON): The System Monitor process (SMON) performs recovery at instance startup if necessary. SMON is also responsible for cleaning up temporary segments that are no longer in use.
- Process monitor process (PMON): PMON registers information about the instance and dispatcher processes with the network listener. PMON periodically checks the status of dispatcher and server processes, and restarts any that have stopped running (but not any that Oracle Database has terminated intentionally).
The Process Monitor process (PMON) performs process recovery when a user process fails. PMON is responsible for cleaning up the database buffer cache and freeing resources that the user process was using.
- Recoverer process (RECO): The Recoverer process (RECO) is a background process that is used with the distributed database configuration.
Automatically connects to other databases involves in in-doubt distributed transactions and resolves them automatically. Removes any row that correspond to in-doubt transactions.
- Archiver processes (ARCn): The archiver processes (ARCn) copy redo log files to a designated storage device after a log switch has occurred. ARCn processes are present only when the database is in ARCHIVELOG mode and automatic archiving is enabled.
- Queue monitor processes (QMNn)
- Job queue coordinator (CJQ0)
- Job slave processes (Jnnn)
- ohasd: Oracle High Availability Service daemon that is responsible to starting Oracle Clusterware processes
- ocssd: Cluster Synchronization Service daemon
- diskmon: Disk Monitor daemon that is responsible for input and output fencing for HP Oracle Exadata Storage Server
- cssdagent: Starts, stops and check the status of the CSS daemon, ocssd
- oraagent: Extend clusterware to support Oracle-specific requirements and complex resources
- orarootagent: A specialized Oracle agent process that helps manage resources owned by root, such as the network.
Some components Storage structures:
The files that are in oracle database are
Required:
- Control Files: Contain data about the database itself (that is, physical database structure information). These files are critical to the database. Without them, you cannot open data files to access the data in the database. It can also contain metadata related to backups.
- Data Files: Contain the user or application data of the database, as well as metadata and the data dictionary.
- Parameter File/Secured Parameter File(Pfile/SPfile): Is used to define how the instance is configured when it starts up
- Online redo log Files: Allow for instance recovery of the database. If the database server crashes and does not lose any data files, the instance can recover the database with the information in these files.
- Archive redo log Files: Contain an ongoing history of the data changes (redo) that are generated by the instance. Using these files and a backup of the database, you can recover a lost data file. That is, archive logs enable the recovery of restored data files.
- Password Files: Allows users using the sysdba, sysoper, and sysasm roles to connect remotely to the instance and perform administrative tasks
- Backup Files: Are used for database recovery. You typically restore a backup file when a media failure or user error has damaged or deleted the original file.
- Trace Files: Each server and background process can write to an associated trace file. When an internal error is detected by a process, the process dumps information about the error to its trace file. Some of the information written to a trace file is intended for the database administrator, whereas other information is for Oracle Support Services.
- Alert log File: These are special trace entries. The alert log of a database is a chronological log of messages and errors. Oracle recommends that you review the alert log periodically.
Physical and logical structures of Oracle Database:
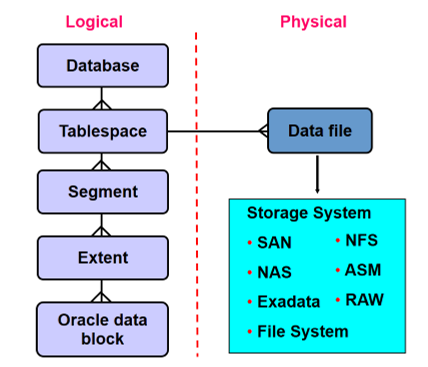

A database is logically divided into two or more table spaces, each table spaces has some extents and each extent is again divided into data blocks.
Data Block: In oracle the data is stored in the form of blocks, one data block corresponds to a specific number of bytes of physical space on a disk, the data block size is specified for each tablespace when its created.
Extent: Group of data blocks combined called as Extent, An extent is a specific number of contiguous Oracle data blocks (obtained in a single allocation) that are used to store a specific type of information.
Segments: A segment is a set of extents allocated for a certain logical structure, some of the segments are
- Data Segments
- Index segments
- Undo Segments
- Temporary Segments

- Segments exists in tablespace.
- Segments are collection of extent.
- Extents are the collection of data blocks.
- Data blocks are mapped to Disk Blocks in storage system
Comments
Post a Comment